Clik here to view.

在看完了GeForce RTX 4090的效能測試後,接著我們就繼續來分析全新的Ada Lovelace繪圖架構,深入瞭解其改進之處。
運算架構組成
首先我們以GeForce RTX 4090的AD102 GPU來說明Ada Lovelace繪圖架構的運算單元組成方式。
完整的AD102具有12組圖像處理叢集(Graphics Processing Clusters,GPC)、72組材質處理叢集(Texture Processing Clusters,TPC)、144組串流多重處理器(Streaming Multiprocessors,SM),總共有18432組CUDA核心。至於記憶體部分,則是由12組寬度為32bit的控制器組成總寬度為384bit的記憶體通道,此外還有獨立的光流加速器(Optical Flow Accelerator),以及NVENC編碼器、NVDEC解碼器各3組,並透過PCIe Gen 4x16匯流排連接至主機板。
NVIDIA也在Ada Lovelace白皮書中提到,每組SM中具有2個FP64運算核心(總量為288個),由於FP64資料格式程式的執行效率僅有FP32的1/64,因此這些少量的FP64運算核心目的僅為確保FP64程式能夠正常運作。
與前代架構相比,Ada Lovelace的SM具有2倍的運算效能與電力效率,因此能在不增加電力消耗的前提下,達到相同效能輸出,或是在消耗相同電力的情況下,將效能輸出提升2倍。
而實際搭載於GeForce RTX 4090的AD102則屏蔽1組GPC,因此總共少了6組TPC、12組SM、1536組CUDA核心,詳細規格請參考下表。此外GeForce RTX 4090也僅保留2組NVENC編碼器與1組NVDEC解碼器,但記憶體控制器與光流加速器則無異動。
(若手機版瀏覽器無法顯示表格,請點我看完整表格)
| NVIDIA例代顯示卡規格對照表 | |||||
| 項目 | GeForce RTX 2080 Ti | GeForce RTX 3090 Ti | GeForce RTX 4080 12GB | GeForce RTX 4080 16GB | GeForce RTX 4090 |
| GPU代號 | TU102 | GA102 | AD104 | AD103 | AD102 |
| GPC數量 | 6 | 7 | 5 | 7 | 11 |
| TPC數量 | 34 | 74 | 30 | 38 | 64 |
| SM數量 | 68 | 84 | 60 | 76 | 128 |
| CUDA核心數量 | 4352 | 10752 | 7680 | 9728 | 16384 |
| 光流處理器數量(OFA) | 無 | 126 | 305 | 305 | 305 |
| 核心Boost時脈 | 1635MHz | 1860MHz | 2610MHz | 2505MHz | 2520MHz |
| FP32運算效能 | 14.2TFLOPS | 40TFLOPS | 40.1TFLOPS | 48.7TFLOPS | 82.6TFLOPS |
| Tensor核心數量 | 544(第2代) | 336(第3代) | 240(第4代) | 304(第4代) | 512(第4代) |
| Tensor FP16運算效能(正常/稀疏運算) | 113.8TFLOPS | 160/320TFLOPS | 160.4/320.8TFLOPS | 194.9/389.8TFLOPS | 330.3/660.6TFLOPS |
| Tensor FP8運算效能(正常/稀疏運算) | 不支援 | 不支援 | 320.7/641.4TFLOPS | 389.8/779.8TFLOPS | 660.6/1321.2TFLOPS |
| RT核心數量 | 68(第1代) | 84(第2代) | 60(第3代) | 76(第3代) | 128(第3代) |
| RT運算效能 | 42.9TFLOPS | 78.1TFLOPS | 92.7TFLOPS | 112.7TFLOPS | 191TFLOPS |
| 材質單元數量 | 272 | 336 | 240 | 304 | 512 |
| 材質填充率(Gigatexels/s) | 444.7 | 625 | 626.4 | 761.5 | 1290.2 |
| ROP數量 | 88 | 112 | 80 | 112 | 176 |
| 像素填充率(Gigapixels/s) | 143.9 | 208.3 | 208.8 | 280.6 | 443.5 |
| 顯示記憶體容量、種類 | 11GB GDDR6 | 24GB GDDR6X | 12GB GDDR6X | 16GB GDDR6X | 24GB GDDR6X |
| 顯示記憶體通道寬度 | 352bit | 384bit | 192bit | 256bit | 384bit |
| 顯示記憶體傳輸速度 | 14Gbps | 21Gbps | 21Gbps | 22.4Gbps | 21Gbps |
| 顯示記憶體頻寬 | 616GB/s | 1008GB/s | 504GB/s | 716.8GB/s | 1008GB/s |
| L1快取記憶體容量 | 6.375MB | 10.5MB | 7.5MB | 9.5MB | 16MB |
| L2快取記憶體容量 | 5.5MB | 6MB | 48MB | 64MB | 72MB |
| 影像編碼加速器 | 第7代NVENC | 第7代NVENC | 第8代NVENC x2 | 第8代NVENC x2 | 第8代NVENC x2 |
| 影像解碼加速器 | 第4代NVDEC | 第5代NVDEC | 第5代NVDEC | 第5代NVDEC | 第5代NVDEC |
| PCIe介面 | PCIe Gen 3x16 | PCIe Gen 4x16 | PCIe Gen 4x16 | PCIe Gen 4x16 | PCIe Gen 4x16 |
| TGP(顯示卡功耗) | 360W | 450W | 285W | 320W | 450W |
| 電晶體數量 | 186億 | 283億 | 358億 | 459億 | 763億 |
| 裸晶尺寸 | 754mm2 | 628.4mm2 | 294.5mm2 | 378.6mm2 | 608.5mm2 |
| 製程 | TSMC 12nm FFN(FinFET NVIDIA) | Samsung 8nm 8N NVIDIA客製化製程 | TSMC 4nm NVIDIA客製化製程 | TSMC 4nm NVIDIA客製化製程 | TSMC 4nm NVIDIA客製化製程 |
Image may be NSFW.
Clik here to view.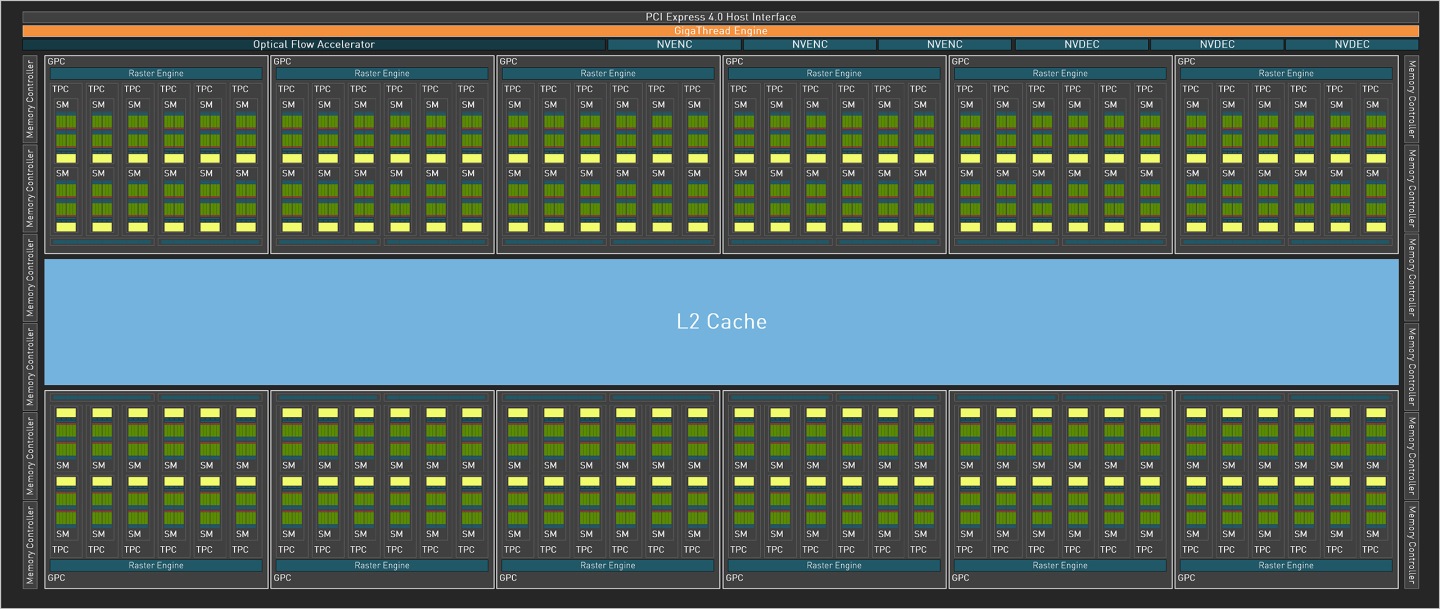
Image may be NSFW.
Clik here to view.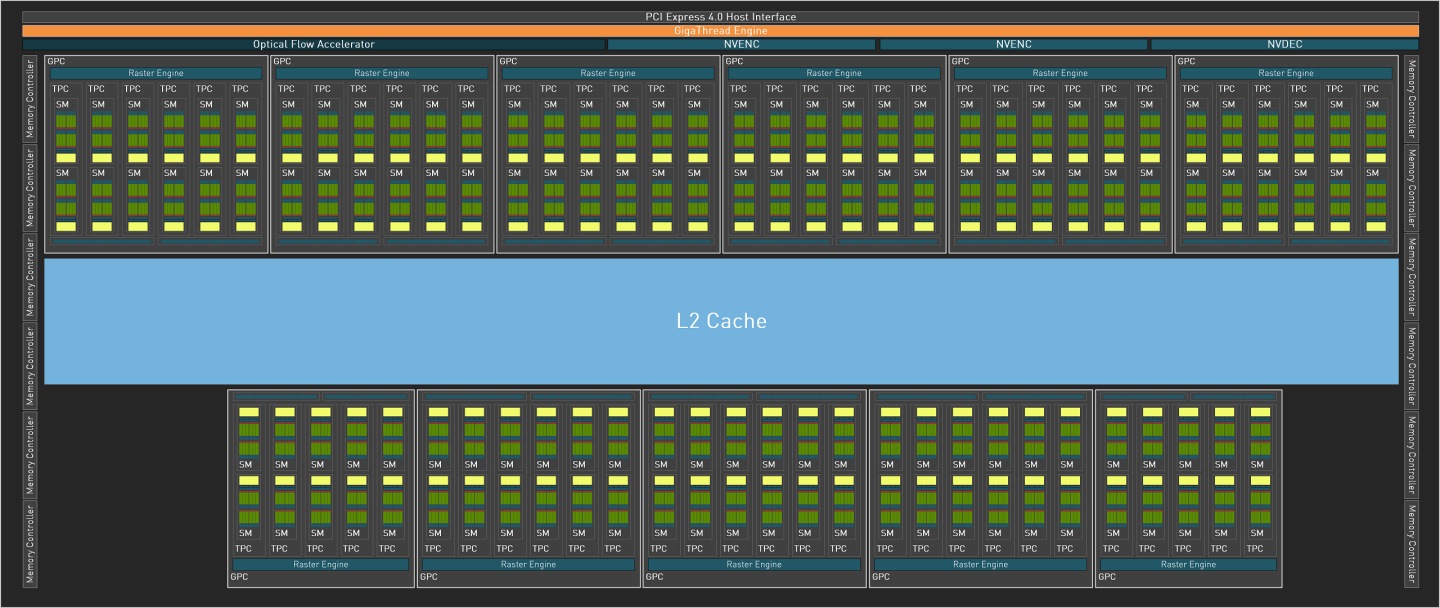
Image may be NSFW.
Clik here to view.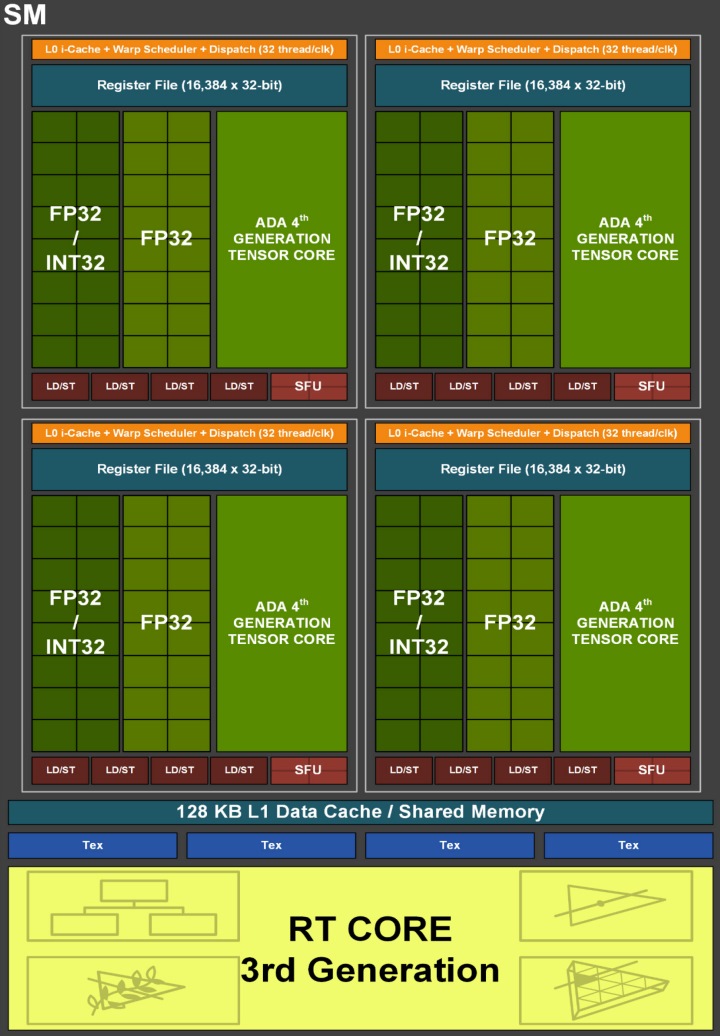
Image may be NSFW.
Clik here to view.
Image may be NSFW.
Clik here to view.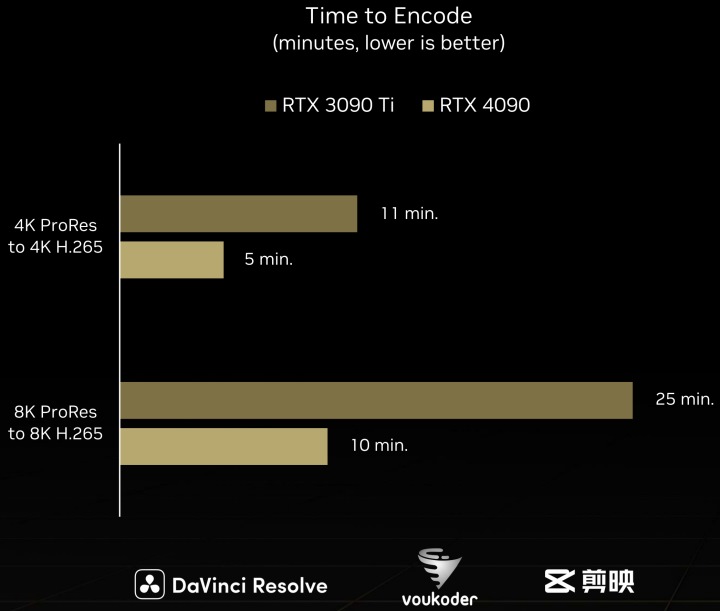
(下頁還有光線追蹤效能提升的解說)
光線追蹤再加速
RTX 20與RTX 30世代的Turing、Ampere繪圖架構具有加速BVH(Bounding Volume Hierarchy,偵測光線是否有「碰撞」到物體)的Box Intersection Engine運算單元,以及加速多邊型與光線邊框相交測試的Triangle Intersection Engine運算單元,能夠有效協助降低SM的運算負載,讓SM能執行更多傳統的頂點、像素運算。
RTX 40世代的Ada Lovelace繪圖架構除了保留這2種運算單元之外,還將光線多邊形交會(Ray-Triangle Intersection)的運算吞吐量提升2倍,並加入了可以提供透明貼圖光線偵測速度2倍的透明迷你貼圖引擎(Opacity Micromap Engine),以及能夠極大幅提升BVH建構速度與降低佔用容量的迷你網格位移引擎(Displaced Micro-Mesh Engine)。
首先我們先來瞭解透明迷你貼圖引擎的概念。許多遊戲開發者會利用材質貼圖的Alpha通道(透明度)來瞄繪複雜的形狀或半透明物品,舉例來說樹葉或火燄等複雜形狀可以透過少量多邊形搭配Alpha通道完成描繪,並節省許多傳統繪圖的運算需求。不過在光線追蹤繪圖的情況,系統就需要偵測每道光線是否會「穿透」貼圖,而消耗大量運算資源。
在Ada Lovelace導入的透明迷你貼圖引擎,會將貼圖切分為許多細小的虛擬網格,並記錄可供RT核心直接查詢的透明度狀態,若光線碰到標記為「不透明」的區域則會回傳光線碰撞的結果,若碰到「透明」區域則會讓光線繼續前進並找尋下一個碰撞點。如果碰到「未知」區域,系統才會將運算負載交還給SM並運算碰撞狀況,如此一來便可省下可觀的運算量。
迷你網格位移引擎則是可以解決用於描繪物件的多邊形數量越來越多,所衍生的BVH運算量與占用記憶體空間問題。其概念為使用單一的基本三角形(Base Triangle)搭配位移映射圖(Displacement Map),來模擬使用大量多邊型所繪製的物件,如此一來便可簡化光線碰撞的偵測演算,除了可以大幅提升BVH的運算速度,還能大量降低占用記憶體空間,進而提升光線追蹤的整體運算效能。
Image may be NSFW.
Clik here to view.
Image may be NSFW.
Clik here to view.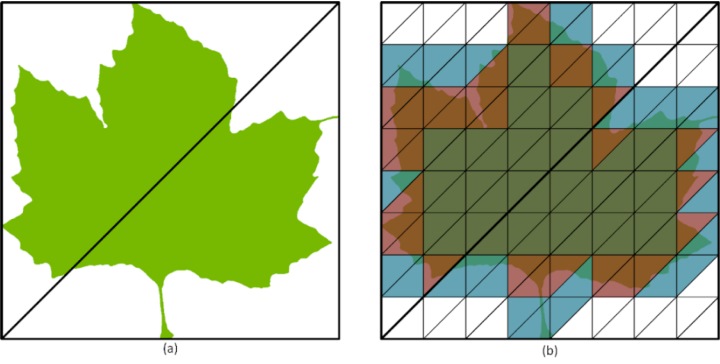
Image may be NSFW.
Clik here to view.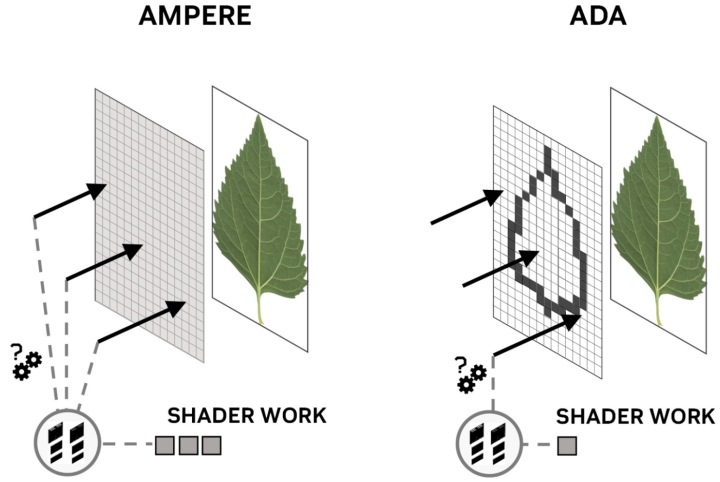
Image may be NSFW.
Clik here to view.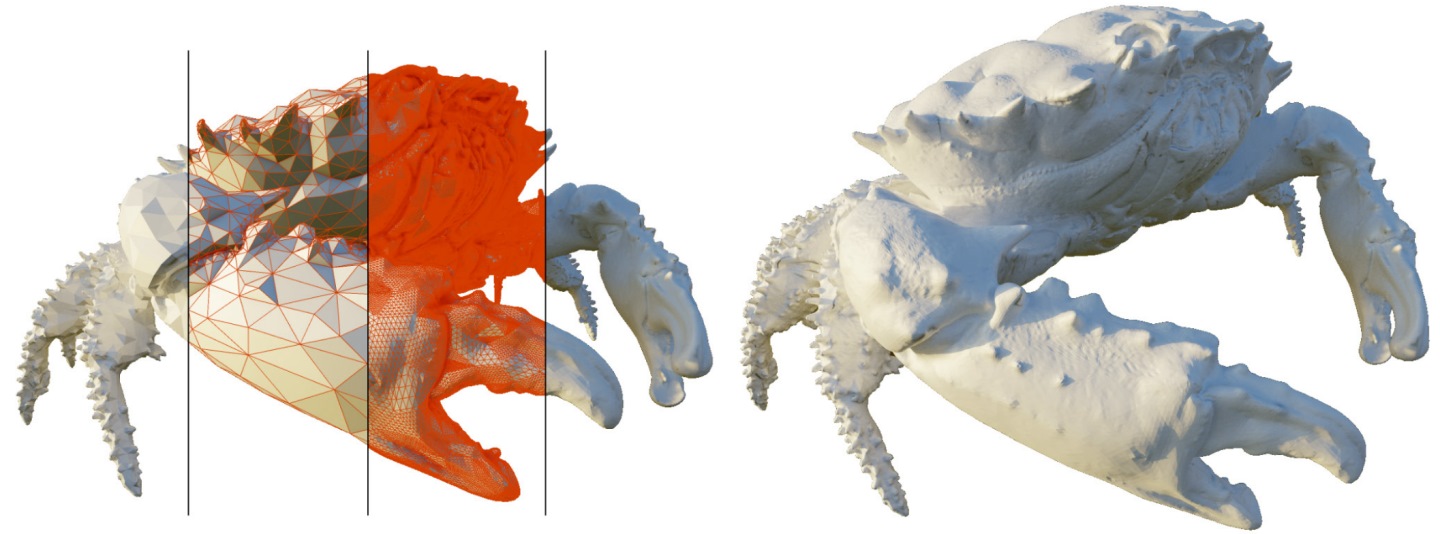
Image may be NSFW.
Clik here to view.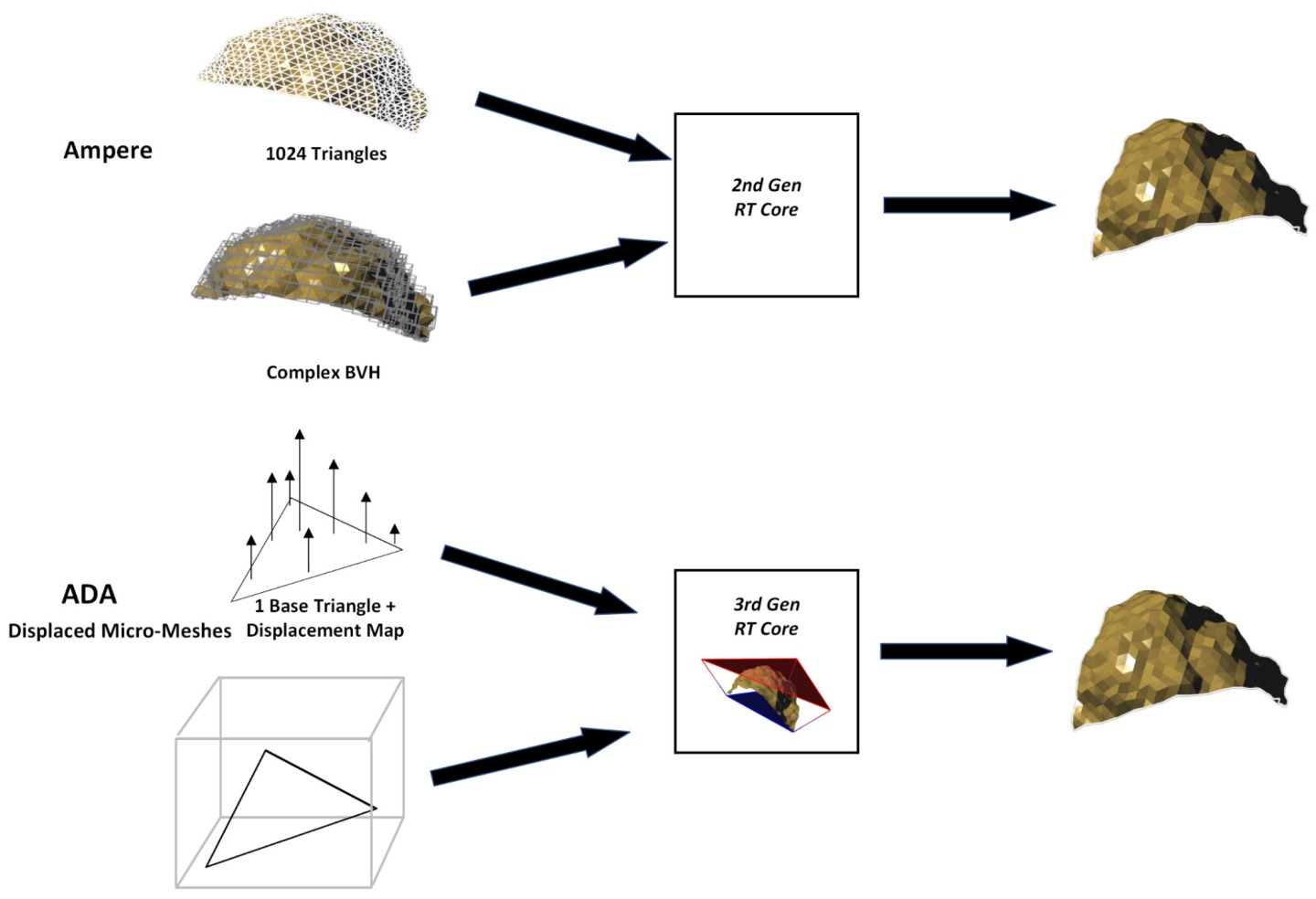
Image may be NSFW.
Clik here to view.
亂序執行效率更高
為了要提高光線追蹤繪圖的逼真程度,就必需要追加光線的數量與反彈次數,並承受運算需求增加的代價,另外隨機路徑追蹤演算法與複雜的材料表面也都會增加運算複雜度。這些狀況會造成2種不同型式的分歧,執行分歧是同一渲染器內的執行緒處理不同的渲染或程式指令,而資料分歧則是執行緒需要處理難以合併或暫存的記憶體資料,這2種分歧都對於擅長處理大量同質工作負載的繪圖處理器(GPU)相當不友善,並會拖累效能表現。在光線追蹤繪圖中,反射、間接照明和半透明等效果也會造成上述的分歧問題。
Ada Lovelace繪圖架構導入的渲染器執行重新排序(Shader Execution Reordering,SER)能夠即時調度工作分配,以達到更理想的執行效率與資料結構,並發揮提升效能表現的功效。
由於SER技術會大量占用快取記憶體,因此Ada Lovelace系列顯示卡度大幅提升L2快取記憶體的容量,以GeForce RTX 3090 Ti與GeForce RTX 4090相比,彼此的L2快取記憶體容量由6MB大幅提升至72MB。雖然先前的顯示卡架構在理論上也能支援SER技術,但受到快取記憶體容量限制,所以效果可能不會太理想。
根據NVIDIA進行的分析,SER能夠提升2倍光線追蹤繪圖效能,並在《電馭叛客2077》Overdrive Mode超高畫質模式下,提升整體FPS效能達44%,可見這項功能的對遊戲體驗有相當大的幫助。
由於SER完全由API所控制,所以遊戲開發者可以透過NVAPI輕鬆導入SER功能(不過這也代表現有遊戲需要透過更新才能支援SER),NVIDIA也表示他們正在開發NSight圖形渲染器的新功能,以簡化SER的最佳化,並與Microsoft和其他公司合作,將SER推廣為標準繪圖API,以讓SER更加普及。
Image may be NSFW.
Clik here to view.
Image may be NSFW.
Clik here to view.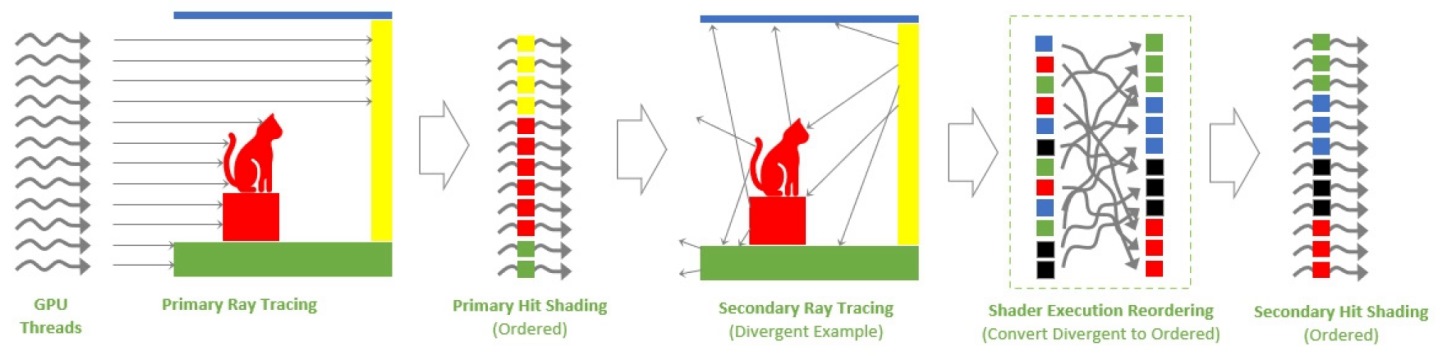
Ada Lovelace除了大幅翻新光線追蹤繪圖的運算架構外,在透過AI進行畫面升頻的DLSS 3技術也有許多亮點,筆者將在下一篇文章中進行介紹與實際測試。
系列文章:
NVIDIA GeForce RTX 4090創始版開箱搶先看,新世代卡王即將降臨!
GeForce RTX 4090效能實測,新世代卡王暢玩4K光線追蹤
NVIDIA Ada Lovelace架構解析(一):光線追蹤效能大爆發(本文)
NVIDIA Ada Lovelace架構解析(二):實測DLSS 3讓遊戲效能再次翻倍(製作中)
加入電腦王Facebook粉絲團