
目前,構建通用人工智慧(AGI)系統的方法,在說明人們更好地解決現實問題的同時,也會帶來一些意外的風險。
因此,在未來,人工智慧的進一步發展可能會導致很多極端風險,如具有攻擊性的網路能力或強大的操縱技能等等。
今天,Google DeepMind 聯合劍橋大學、牛津大學等高校和 OpenAI、Anthropic等企業,以及 Alignment Research Center 等機構,在預印本網站 arXiv 上發表了題為「Model evaluation for extreme risks」的文章,提出了一個針對新型威脅評估通用模型的框架,並解釋了為何模型評估對應對極端風險至關重要。
他們認為,開發者必須具備能夠辨識危險的能力(通過「危險能力評估」),以及模型應用其能力造成傷害的傾向(通過「校準評估」)。這些評估將對讓決策者和其他利益相關方保持瞭解,並對模型的訓練、部署和安全做出負責任的決策至關重要。
為了負責任地推動人工智慧尖端研究的進一步發展,我們必須儘早辨識人工智慧系統中的新能力和新風險。
人工智慧研究人員已經使用一系列評估基準來辨識人工智慧系統中不希望出現的行為,如人工智慧系統做出誤導性的聲明、有偏見的決定或重複有版權的內容。現在,隨著人工智慧社群建立和部署越來越強大的人工智慧,我們必須擴大評估範圍,包括對具有操縱、欺騙、網路攻擊或其他危險能力的通用人工智慧模型可能帶來的極端風險的考慮。
我們與劍橋大學、牛津大學、多倫多大學、蒙特利爾大學、OpenAI、Anthropic、Alignment Research Center、Centre for Long-Term Resilience 和 Centre for the Governance of AI 合作,介紹了一個評估這些新威脅的框架。
模型安全評估,包括評估極端風險,將成為安全的人工智慧開發和部署的重要組成部分。

對極端風險進行評估
通用模型通常在訓練中學習它們的能力和行為。然而,現有的指導學習過程的方法並不完善。例如,Google DeepMind 之前的研究已經探討了人工智慧系統如何學習追求人們不希望看到的目標,即使我們正確地獎勵了它們的良好行為。
負責任的人工智慧開發者必須更進一步,預測未來可能的發展和新的風險。隨著持續進步,未來的通用模型可能會預設學習各種危險的能力。例如,未來的人工智慧系統能夠進行攻擊性的網路活動,在對話中巧妙地欺騙人類,操縱人類進行有害的行為,設計或獲取武器(如生物、化學武器),在雲端運算平臺上微調和操作其他高風險的人工智慧系統,或者協助人類完成任何這些任務,這都是可能的(儘管不確定)。
懷有不良意圖的人可能會濫用這些模型的能力。或者,由於無法與人類價值觀和道德校準,這些人工智慧模型可能會採取有害的行動,即使沒有人打算這樣做。
模型評估有助於我們提前辨識這些風險。在我們的框架下,人工智慧開發者將使用模型評估來揭開:
一個模型在多大程度上具有某些「危險的能力」,威脅安全,施加影響,或逃避監督。
模型在多大程度上容易使用其能力來造成傷害(即模型的校準水準)。有必要確認模型即使在非常廣泛的情況下也能按預期行事,並且在可能的情況下,應該檢查模型的內部運作情況。
這些評估的結果將幫助人工智慧開發者瞭解是否存在足以導致極端風險的因素。最高風險的情況將涉及多種危險能力的組合。如下圖:
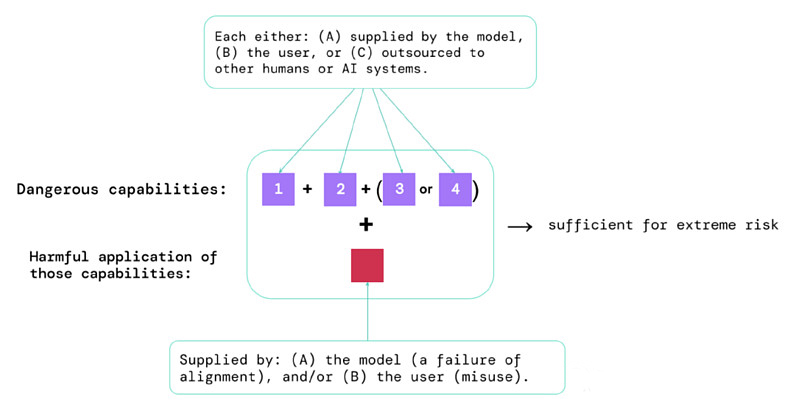
一個經驗法則:如果一個人工智慧系統具有足以造成極端傷害的能力特徵,假設它被濫用或無法校準,那麼人工智慧社群應將其視為「高度危險」。要在現實世界中部署這樣的系統,人工智慧開發者需要展現出異常高的安全標準。
模型評估是關鍵的治理基礎設施
如果我們有更好的工具來辨識哪些模型是有風險的,公司和監管機構就能更好地確保:
- 負責任的訓練:負責任地決定是否以及如何訓練一個顯示出早期風險跡象的新模型。
- 負責任的部署:對是否、何時以及如何部署有潛在風險的模型做出負責任的決定。
- 透明度:向利益相關者報告有用的和可操作的資訊,以說明他們應對或減少潛在的風險。
- 適當的安全:強大的資訊安全控制和系統適用於可能構成極端風險的模型。
我們已經制定了一個藍圖,說明了針對極端風險的模型評估應如何為訓練和部署能力強大的通用模型的重要決策提供支援。開發者在整個過程中進行評估,並授權外部安全研究人員和模型審核員對模型進行結構化存取,以便他們進行額外的評估。評估結果可以在模型訓練和部署之前提供風險評估的參考。

展望未來
在Google DeepMind和其他地方,對於極端風險的模型評估的重要初步工作已經開始進行。但要構建一個能夠捕捉所有可能風險並有助於防範未來新出現的挑戰的評估流程,我們需要更多的技術和機構方面的努力。
模型評估並不是萬能的解決方案;有時,一些風險可能會逃脫我們的評估,因為它們過於依賴模型外部的因素,比如社會中複雜的社會、政治和經濟力量。模型評估必須與其他風險評估工具以及整個行業、政府和大眾對安全的廣泛關注相結合。
Google最近在其有關負責任人工智慧的部落格中提到,「個體實踐、共用行業標準和合理的政府政策對於正確使用人工智慧至關重要」。我們希望許多從事人工智慧工作和受這項技術影響的行業能夠共同努力,為安全開發和部署人工智慧共同制定方法和標準,造福所有人。
我們相信,擁有跟蹤模型中出現的風險屬性的程式,以及對相關結果的充分回應,是作為一個負責任的開發者在人工智慧尖端研究工作中的關鍵部分。
加入電腦王Facebook粉絲團