
NVIDIA在GTC 24春季場發表了具有6大創新的Blackwell架構GPU,不但提供更強悍的效能,更降低25倍總體擁有成本,還能透過先進管理功能縮短伺服器停機時間。
裸晶尺寸達到現今光罩極限
Blackwell是專為資料中心處理生成式AI而設計GPU,它採用TSMC(台積電)4NP製程節點,由2.08兆個電晶體構成,是目前世界上最大型的GPU。其晶片由2組裸晶(Die)所構成,每組裸晶的尺寸達到現今半導體製程中光罩的極限,並透過頻寬高達10 TB/s的NV-HBI(NVIDIA High-Bandwidth Interface)晶片對晶片互連(Chip-to-Chip Interconnection)相連,讓2組裸晶成為單一晶片並確保記憶體一致性(Coherent),能夠共享容量高達192 GB的HBM3e高頻寬記憶體。
- 延伸閱讀:
- GTC 24:Blackwell全新架構帶來5倍效能表現(本文)
- GTC 24:Blackwell架構詳解(下),看懂B100、B200、GB200、GB200 NVL72成員的糾結瓜葛(工作中)
- GTC 2024春季場系列報導目錄
Blackwell在Tensor核心(硬體層面)與TensorRT-LLM、Nemo運算框架(軟體層面)協同運作之下支援第2代Transformer引擎,能夠加速大型語言模型與混合專家(Mixture-of-Experts)AI模型在訓練與推論時的運算效能,並且能夠支援包含由社群定義的FP4與FP6資料類型的浮點運算,以及由社群定義的微擴充格式(Microscaling Formats),能夠提供高準確度與高吞吐量的運算成效。
全新的Micro-Tensor Scaling技術能夠支援動態範圍管理演算法(Dynamic Range Management Algorithm)、精細粒度擴充(Fine-Grain Scaling),並支援FP4資料類型運算,且最佳化運算效能與精準度,讓Blackwell的FP4 Tensor核心Core能夠達到雙倍記憶體參數頻寬,並讓GPU能夠容納雙倍尺度的AI模型。





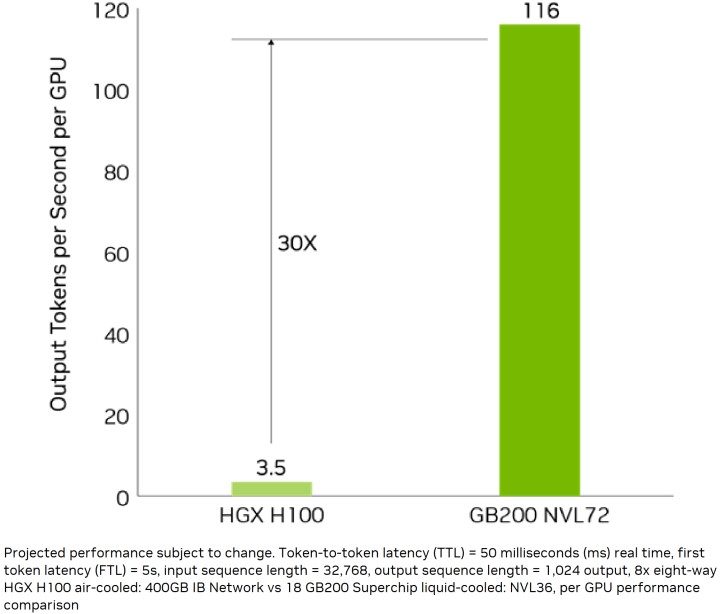
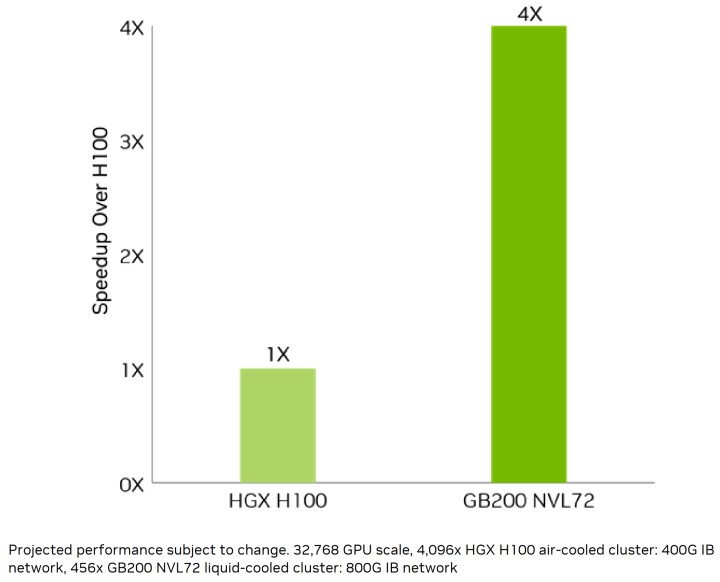
強化伺服器競爭力
Blackwell GPU也加入了許多專為企業與資料中心應用設計的功能,例如RAS引擎(Reliability, Availability,and Serviceability Engine,可靠性、可用性和可維護性引擎)會透過完整的自我檢查機制搭配由AI驅動的大數據分析,預測系統中可能會出狀況的檢查點(Chickpoint),讓維護團隊可以即早處理,或是在非不得以需要關機時,也可以安排在衝擊最小的時間簡進行維護,大幅縮短伺服器的停機時間(Downtime)。
NVIDIA也將機密運算(Confidential Computing)功能由CPU推廣至GPU,擴大可信任執行環境(Trusted Execution Environment,TEE)的範圍,讓Blackwell 成為首款支援TEE-I/O的GPU,能夠提供更快、更安全、可證明(Evidence-Based Attestable)的資安保護,並且提供幾乎等同於未加密模式的資料吞吐效能,讓客戶能夠確保AI智慧財產權,並確保機密AI訓練、推論理與聯邦學習(Federated Learning)的安全性。
為了提高資料傳輸的效率,NVIDIA也一改傳統資料分析和資料庫運算負載透過CPU處理資料緩慢又繁瑣的流程,讓Blackwell GPU加速支援包括Apache Spark在內的資料庫框架,並內建解壓縮效能高達800 GB/s的解壓縮引擎,並支援LZ4、Snappy、Deflate等最新壓縮格式,全面加速資料庫查詢(Database Query)管線效能。
Blackwell GPU搭配頻寬高達8 TB/s的HBM3e高頻寬記憶體以及透過NVLink-C2C互連技術連接至Grace CPU,可以提供18倍於傳統CPU或6倍於前代H100 GPU的查詢效能測試(Query Benchmark),達成資料分析和資料科學(Data Science)的最高運算效能。
上述的效能、運算密度、電力效率、RAS改善,對伺服器的成本都有正面幫助,另一方面NVIDIA也在Blackwell世代積極推動從空冷轉換到水冷的散熱方案,透過散熱工作液體循環於機架內的CPU、GPU等高溫元件以及外部散熱器(Radiator,功能等同於個人電腦水冷系統的散熱排),進一步降低機房空調的能源消耗。
整體而言,在執行萬億組參數的AI模型條件下,採用水冷方案的GB200能較採用空冷的H100降低25倍總體擁有成本(Total Cost of Ownership,TCO),對於資料中心來說相當有吸引力。
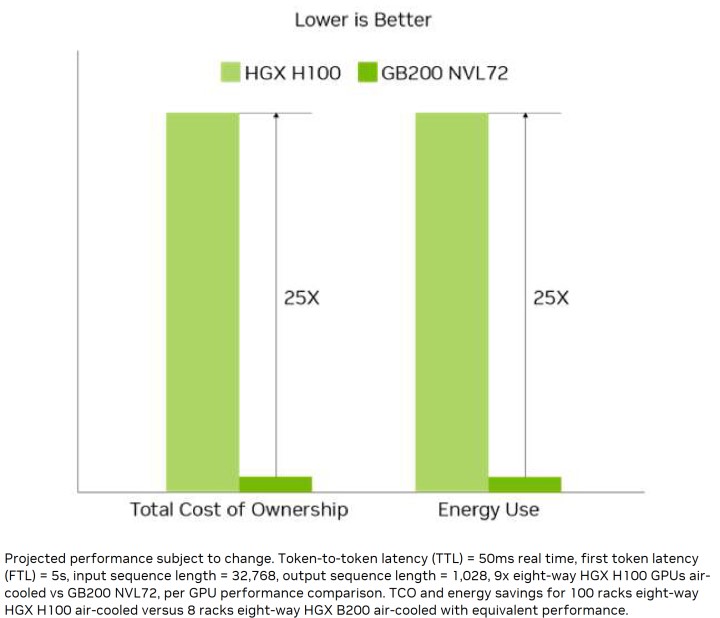
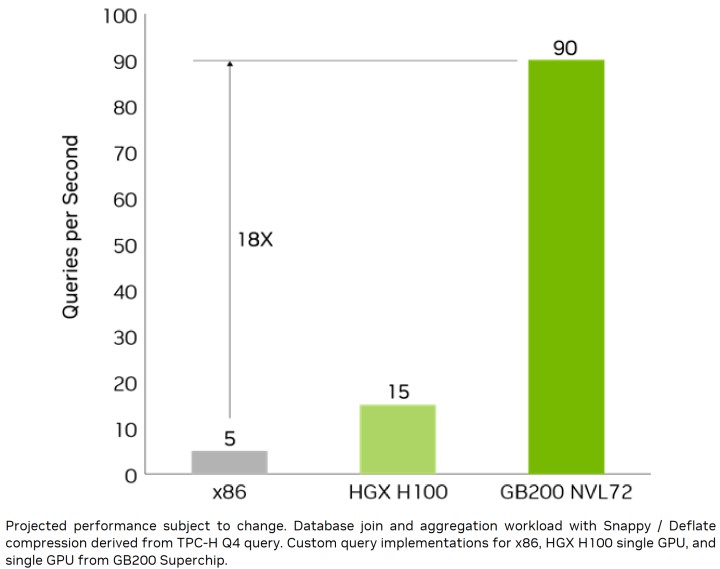
Blackwell GPU不但是目前最強的AI加速運算單元,而且還可透過串接多組GPU方式進行水平式擴充(Scale Out),大幅強化總體效能與吞吐量,筆者將於下篇文章進行詳細說明。
加入電腦王Facebook粉絲團